
Machine learning is the backbone of Artificial Intelligence (AI) because it is through this subfield of AI that machines can learn. All other subfields: natural language Processing (NLP), robotics and computer vision and their respective applications use machine learning algorithms.
That’s why Machine Learning is considered the engine behind the great revolutions we’re seeing in Artificial Intelligence (AI), allowing AI systems to do extraordinary things, like recognizing faces in photos, suggesting songs you’ll love, or even generating stunning images and texts that look like they were created by humans.
But how exactly do machines learn? And why is this so important for the evolution of AI, especially generative AI, which creates new content from existing data? To answer this, we need to understand the different types of machine learning: supervised, unsupervised, and reinforcement. Each of these types is like a different learning method that machines can follow to learn from data and become increasingly intelligent.
Types of Machine Learning
- Supervised Learning: In this type, a machine learns from labeled examples, much like a student learning with guidance from a teacher. The child learning to read and the teacher shows examples of different fruits and how to spell each one.
- Unsupervised Learning: Unlike supervised learning, here the machine explores the data on its own, discovering patterns without clear instructions or examples. In this case, it is as if the child were alone and, when shown images of fruits, the child (without any examples), groups similar fruits together and writes their names.
- Reinforcement Learning: Machines learn by interacting with an environment, the machine is rewarded or penalized for its actions. Imagine that a child is playing a video game and earns points for each fruit he manages to write correctly and is punished when he writes it wrong.
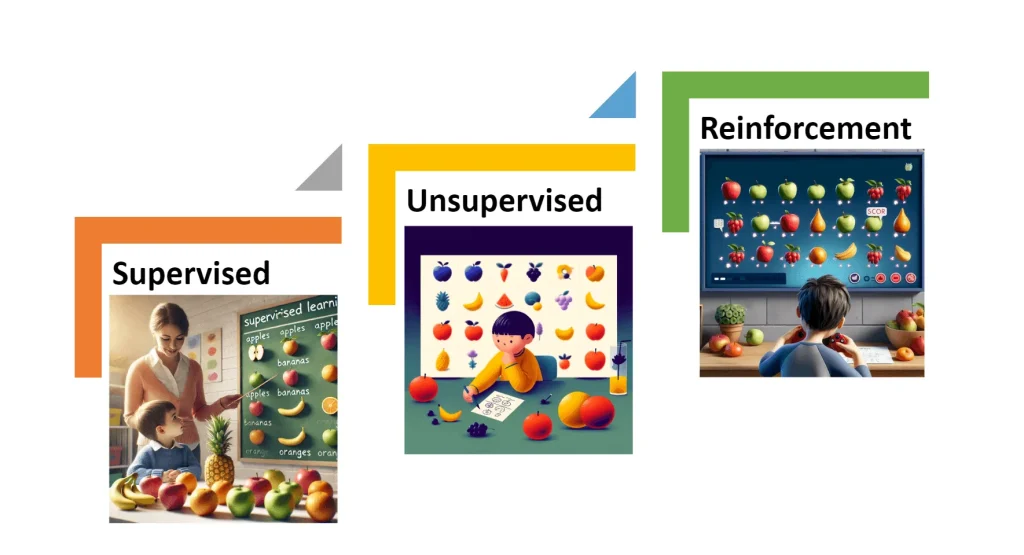
Now that the concept of machine learning types has been explained, let’s understand a little more technically how they work and how they can be applied.
Supervised Learning Applications
Supervised learning is guided by known results (outputs). The machine uses features and labeled data in training and, based on this, defines a relationship between these data.
For example, the machine can be taught to recognize images of apples by providing images of apples and non-apples, each of which must be labeled. Once the relationship in the data has been identified, a model is generated to reproduce the relationship that was learned with new data, as illustrated in the figure below.
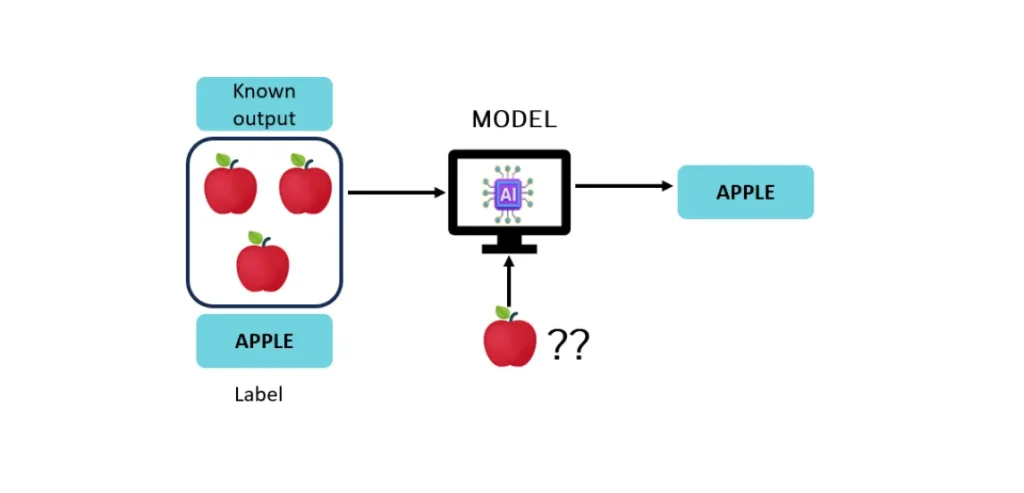
This type of learning has the following applications:
Regression:
Studies the relationships between numerical variables and is used in various predictive analyses, such as demand forecasting, price and sales estimation. Linear Regression and Polynomial Regression are very popular regression algorithms.
Imagine that instead of an image of an apple, the regression algorithm receives financial indicators (input) and instead of the label “apple” it receives the “stock value” (output) of a certain financial company. During the training process, the algorithm finds a relationship between the financial indicators and the stock values so that a model is generated. Based on new values of the financial indicators that are passed as input, the model will be able to predict the stock value.
Classification:
Indicates which class/category an object or data belongs to, and can be used to classify images, customer retention (churn rate), among other options.
Logistic Regression, Decision Tree and Random Forest are examples of algorithms that can be applied to data classification. Here at Loxias, we trained a classification model and created the POP Loxias Index that can classify the popularity of a brand or a person, based on mentions and metrics on social networks. We also trained another model and created the Monitoring Loxias Index that can classify potential crises based on mentions and metrics on social networks.
Unsupervised Learning
In unsupervised learning, there are no previously known patterns to serve as a basis for training the model. In this case, the machine learning algorithm must find patterns on its own. In this type of learning, there is no response, that is, the data has no labels and the result (output) is unknown, since it is the algorithm itself that will identify patterns within the data set.
One of the great advantages of unsupervised learning is precisely the discovery of unknown patterns and the synthesis of a large volume of data. For example, you can pass several images of fruit to a clustering algorithm without providing any labels. All you need to indicate is how many data clusters you want. By providing this amount, the algorithm will calculate the similarity between the fruit images, labeling those that are similar with the same cluster number.
The figure below summarizes this learning process:
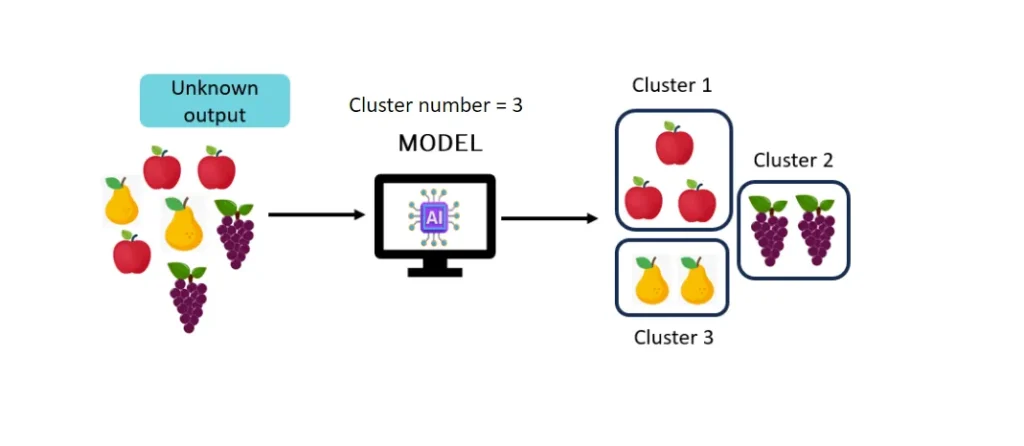
This type of learning has the following applications:
Clustering:
In this case, data is grouped according to its similarity. It is widely used in marketing to perform data segmentation. K-Means is one of the best-known unsupervised algorithms.
Association:
This method consists of finding frequent patterns of associations between the attributes of a data set. It is often used to identify rules that describe large parts of the data, such as people who buy X also tend to buy Y.
Summarization:
This method used to optimize points, paths, spaces or to perform dimensionality reduction and topic modeling. Here at Loxias, we are experimenting with the use of LLMs, such as BERT and its derivatives, to perform topic modeling, that is, to summarize large volumes of data from social media mentions, with the aim of identifying relevant content/topics.
Unfortunately, there is some confusion between classification and clustering that needs to be clarified. Classification is a task that requires supervised learning, that is, it is necessary to know in advance which class a given data record belongs to. Clustering, on the other hand, is an unsupervised learning type, where it is not necessary for the data to be labeled.
The Kaggle GIF below illustrates this difference well:
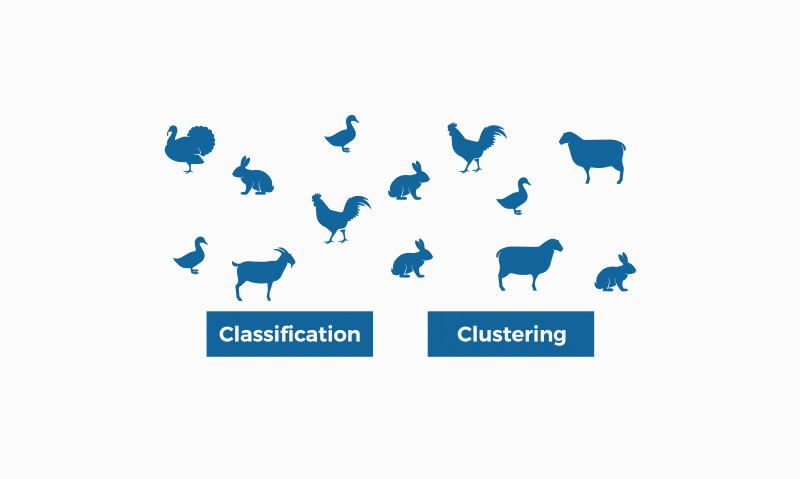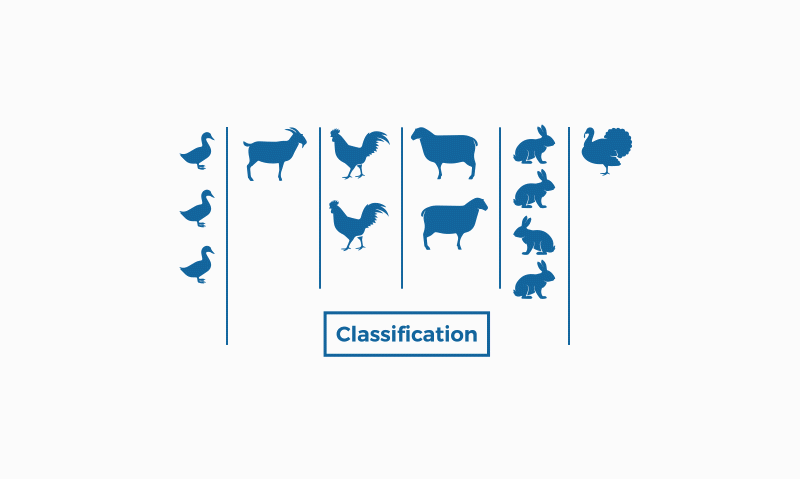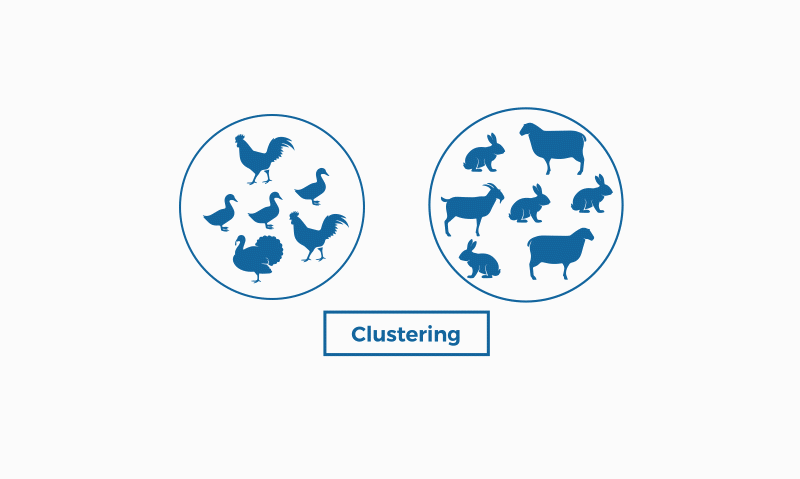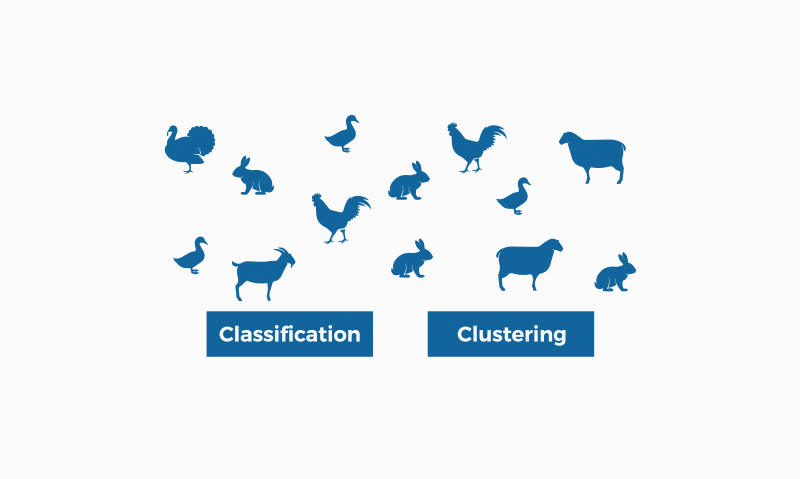
in classification, it is necessary to know in advance who each of the animals is so that a model can be generated to classify them (duck, rabbit, etc.). Clustering, on the other hand, does not need to know the result in advance, as it is a task that uses unsupervised learning, it can group the animals on its own, based on the similarities and differences between them (if it has feathers, wings and two legs, it groups them as being in the same group, if it has four legs and no wings, it marks them as being in another group).
Reinforcement Learning
Reinforcement learning is based on feedback from previous interactions. This type of learning continually improves the model. It uses the concept of reward and punishment. A reward is given if a response is correct and a punishment is given if a response is incorrect. It is widely used in models that learn from games, decision-making systems, and robot navigation.
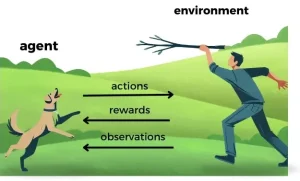
Q-Learning is an example of an algorithm used in reinforcement learning. In this type of learning, it is necessary to define who the agent is, what the environment is, the actions, and the status.
An example of an app that uses reinforcement learning that everyone knows is ChatGPT’s like button. When you write a prompt and like the answer provided so much that you click the “like button”, you are giving a reward to the model used by ChatGPT, in which case the model understands that the result returned was a correct action.
On the other hand, if the answer provided is not adequate and you do not like it and click the “dislike button”, the model will receive a punishment and learn that the answer provided was not a satisfactory action.
Speaking of ChatGPT, it is worth noting that the training process of the GPT (Generative Pre-trained Transformer) LLM model used by ChatGPT considered the three types of Machine Learning described above.
First, unsupervised training was performed considering a massive scale of textual data, including books, articles, web pages, and other sources of natural language text, the objective of which was to find a pattern in this data. Then, supervised training was applied, where several examples of prompts and responses were passed to the model.
Next, the model was trained with adaptation tasks, which allow the model to adapt to different contexts and natural language domains using a reinforcement learning algorithm that encourages the model to maximize a reward according to a specific task. Finally, the model was refined using the reinforcement learning from human feedback technique. Basically, this technique combines human supervision with machine learning to improve the quality of the outputs generated by the model.
Therefore, it is worth highlighting that the three types of machine learning described in this article are fundamental to the evolution of AI because they allow machines to acquire knowledge and skills in varied and flexible ways. This not only accelerates the development of intelligent systems, but also opens the door to the creation of new technologies, such as generative AI, which can create new and innovative content.
Imagine a machine that, by learning, is able to create music, art or even write stories — not just copying what already exists, but creating something entirely new. This is the power of machine learning.
Enjoying our content? Sign up for our newsletter and be the first to receive our latest articles. Stay informed on data analytics insights, business intelligence trends, marketing strategies, and the latest advancements in artificial intelligence.